在搭建全栈指标监控体系之前我们要先确认我们的环境
Master:
172.16.11.142 k8s-master
Worker:
172.16.11.145 k8s-worker1
172.16.11.146 k8s-worker2
Dashboard 地址:
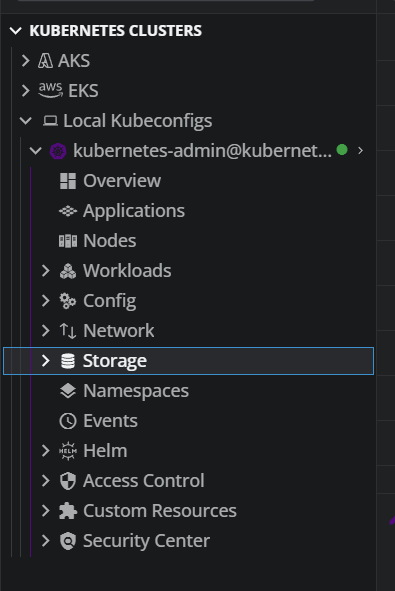
我现在 VS Code 里已经能识别到本地 kubeconfig,说明:
kubectl 配置基本正常
VS Code Kubernetes 插件能看到集群
可以在图形界面查看 Nodes / Workloads / Config / Storage / Helm 等资源
我的监控系统部署方式
我这个是三节点 kubeadm 集群,适合先部署:
kube-prometheus-stack
kube-prometheus-stack是什么呢
kube-prometheus-stack 是 Kubernetes 里最常用的一套监控系统 Helm Chart
人话版:
它不是单独一个软件,而是 一整套 K8s 监控套餐,装上之后就能监控:
- Kubernetes 节点状态
- Pod / Deployment / Service 状态
- CPU、内存、磁盘、网络
- API Server、Scheduler、Controller Manager
- etcd
- kubelet
- 容器运行情况
- 告警规则
- Grafana 可视化大屏
我们的部署策略
我的环境是内网实验环境,所以先用 NodePort 暴露访问入口,最简单稳定。
| 服务 | 访问方式 | 端口 |
|---|---|---|
| Grafana | http://172.16.11.142:30030 | 30030 |
| Prometheus | http://172.16.11.142:30090 | 30090 |
| Alertmanager | http://172.16.11.142:30093 | 30093 |
NodePort:NodePort 是 Kubernetes 里的一种 Service 暴露方式。
一句话说:
NodePort = 在每个 K8S 节点上开一个端口,让外部可以通过 “节点 IP + 端口” 访问 Pod
Grafana:Grafana 是一个开源的 监控数据可视化平台。
一句话理解:
Grafana = 把 Prometheus、数据库、日志系统里的数据做成漂亮仪表盘的工具。
Prometheus:Prometheus 是一个开源的 监控与告警系统。
一句话理解:
Prometheus = 负责采集、保存、查询监控指标的“监控数据库”。
Alertmanager:Alertmanager 是 Prometheus 监控体系里的 告警处理器。
一句话理解:
Prometheus 发现问题,Alertmanager 负责把告警整理好,再通知人
后面如果要做生产化,再改成:
Ingress + 域名 + HTTPS + 持久化存储 + 告警通知一句话理解
| 模块 | 作用 |
|---|---|
| Ingress | 对外统一入口 |
| 域名 | 用名字访问服务 |
| HTTPS | 加密访问,证书安全 |
| 持久化存储 | Pod 重建数据不丢 |
| 告警通知 | 出问题自动提醒你 |
当前第一步:先确认集群状态
在 k8s-master 上执行:
kubectl get nodes -o wide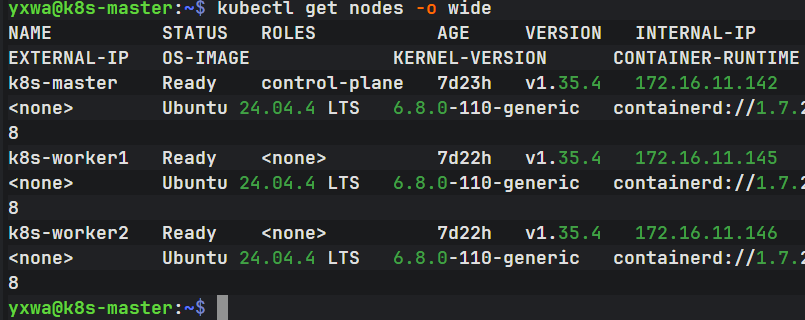
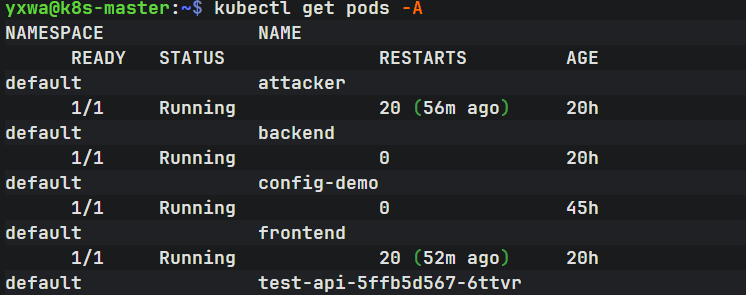
再执行:
kubectl get pods -A
第二步:确认 Helm 有没有安装
执行:
helm version

如果有输出版本号,说明 Helm 可用。
如果提示:
helm: command not found那我们先装 Helm。
curl -fsSL https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 -o get_helm.sh
Helm 已经有了
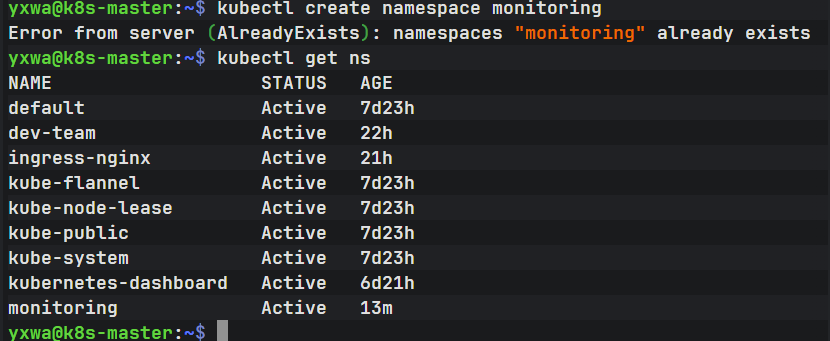
我们下一步只做一件事:创建监控专用命名空间 monitoring。
执行:
kubectl create namespace monitoring然后验证:
kubectl get ns如果提示:
namespace/monitoring created就说明创建成功。
如果提示已经存在,比如:
Error from server (AlreadyExists): namespaces "monitoring" already exists也没关系,说明之前已经创建过了。
下一步:添加 Prometheus Helm 仓库
在 k8s-master 执行:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts然后更新仓库:
helm repo update最后检查一下:
helm search repo prometheus-community/kube-prometheus-stack
但是我发现执行 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts等了很久都没有完成所以我先测试curl -I https://prometheus-community.github.io/helm-charts发现是通的
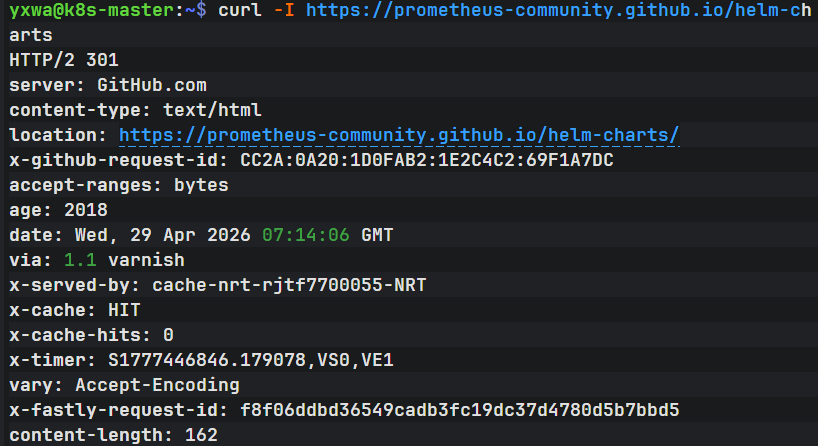
返回了:
HTTP/2 301
location: https://prometheus-community.github.io/helm-charts/说明网络能访问,只是 helm repo add 可能在重定向或下载索引时比较慢
第二步:测试真正的索引文件能不能下载
执行:
curl -L -I https://prometheus-community.github.io/helm-charts/index.yaml这次下载成功了
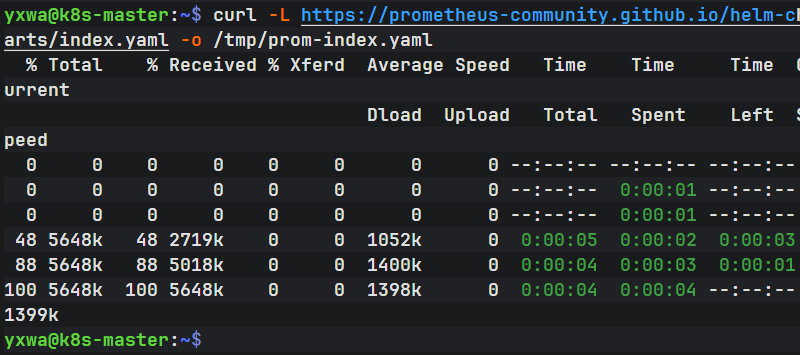
下一步只检查一下文件:
ls -lh /tmp/prom-index.yamlindex.yaml 已经完整下载成功了
现在执行添加 Helm 仓库:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts/如果成功,会看到:
"prometheus-community" has been added to your repositories然后再执行:
helm repo list

Helm 仓库已经添加成功
现在下一步:更新 Helm 仓库索引
执行:
helm repo update

仓库更新成功了
下一步只做一件事:确认能搜到监控包
执行:
helm search repo prometheus-community/kube-prometheus-stack正常会看到类似:
NAME CHART VERSION APP VERSION
prometheus-community/kube-prometheus-stack ...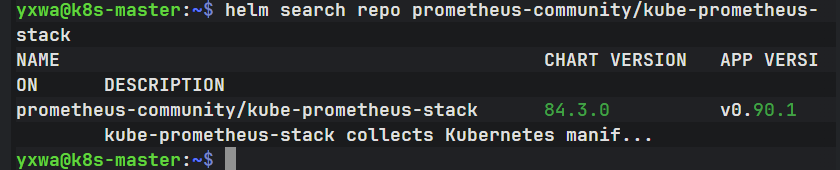
已经搜到了
prometheus-community/kube-prometheus-stack 84.3.0下一步:创建监控配置文件 values-monitoring.yaml
在 k8s-master 执行:
cat > values-monitoring.yaml <<'EOF'
# =========================
# Grafana 配置
# =========================
grafana:
enabled: true
# Grafana 管理员密码
# 默认用户名:admin
adminPassword: "Admin@123456"
service:
# 用 NodePort 暴露,方便浏览器访问
type: NodePort
# Grafana 访问端口:http://任意NodeIP:30030
nodePort: 30030
# =========================
# Prometheus 配置
# =========================
prometheus:
enabled: true
service:
# 用 NodePort 暴露 Prometheus
type: NodePort
# Prometheus 访问端口:http://任意NodeIP:30090
nodePort: 30090
prometheusSpec:
# 指标数据保留 7 天
retention: 7d
# =========================
# Alertmanager 配置
# =========================
alertmanager:
enabled: true
service:
# 用 NodePort 暴露 Alertmanager
type: NodePort
# Alertmanager 访问端口:http://任意NodeIP:30093
nodePort: 30093
EOF创建完后检查一下:
ls -lh values-monitoring.yaml && cat values-monitoring.yaml
配置文件没问题
下一步:开始安装监控系统。
执行:
helm install monitoring prometheus-community/kube-prometheus-stack \
-n monitoring \
-f values-monitoring.yaml但是……我们一直碰到拉不下来/拉下来不行,所以我们换了一点点手段
这次 kube-state-metrics 的问题本质是:
Pod 被调度到了 k8s-worker2,但 worker2 拉取
registry.k8s.io镜像超时,导致 Pod 一直 ImagePullBackOff。
1. 问题现象
我们安装 kube-prometheus-stack 后,发现:
kubectl get pods -n monitoring -o wide里面有一个异常:
monitoring-kube-state-metrics-xxxxx 0/1 ImagePullBackOff k8s-worker2说明 kube-state-metrics 没有正常启动。
2. 查看详细原因
执行:
kubectl describe pod monitoring-kube-state-metrics-xxxxx -n monitoring看到它要拉的镜像是:
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0报错核心是:
dial tcp ...:443: i/o timeout意思是:
k8s-worker2访问registry.k8s.io超时,镜像拉不下来。
3. 尝试过的方案
我们先在 worker2 手动拉原始镜像:
sudo ctr -n k8s.io images pull registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0结果失败:
i/o timeout然后尝试 DaoCloud 的一个旧地址:
docker.m.daocloud.io/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0结果:
403 Forbidden又尝试阿里云地址:
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-state-metrics:v2.18.0结果:
not found4. 最终解决方案
最后使用这个镜像源成功:
sudo ctr -n k8s.io images pull \
m.daocloud.io/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0拉取成功后,我们给它打了一个 原始镜像名标签:
sudo ctr -n k8s.io images tag \
m.daocloud.io/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0 \
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0这一步很关键。
因为 Kubernetes Pod YAML 里写的还是:
registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0所以我们需要让本地 containerd 里也存在这个名字的镜像。
5. 重建 Pod
回到 master 后删除失败 Pod:
kubectl delete pod monitoring-kube-state-metrics-xxxxx -n monitoringK8S 自动重新创建 Pod。
因为 worker2 本地已经有了对应镜像,所以这次不需要再去外网拉取,Pod 正常启动。
最终状态:
monitoring-kube-state-metrics-xxxxx 1/1 Running我们下一步:查看 Service 访问端口,准备打开 Grafana / Prometheus / Alertmanager。
在 master 执行:
kubectl get svc -n monitoring重点看这几个:
Grafana 30030
Prometheus 30090
Alertmanager 30093很好,端口已经出来了
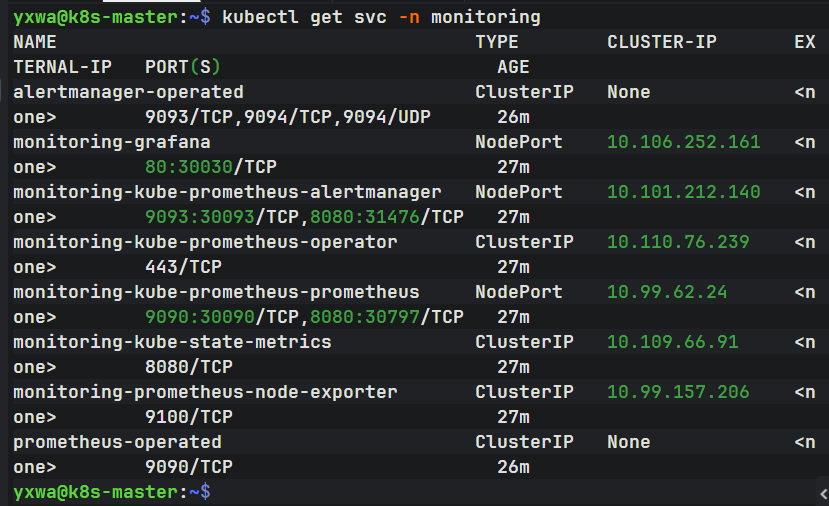
你现在可以访问:
Grafana:
http://172.16.11.142:30030
Prometheus:
http://172.16.11.142:30090
Alertmanager:
http://172.16.11.142:30093下一步打开:
http://172.16.11.142:30030看看 Grafana 能不能进
下一步打开:
http://172.16.11.142:30030看看 Grafana 能不能进
成功打开 Grafana 了,说明 NodePort 暴露没问题
现在登录:
用户名:admin密码:Admin@123456登录后如果提示修改密码,你可以:
1. 改一个新密码2. 或者点 Skip / 跳过进去之后下一步我们看:
点这个:
Kubernetes / Compute Resources / Cluster这个看板主要看:
整个集群 CPU 使用
整个集群内存使用
Pod 资源使用
Namespace 资源占用然后再看节点:
Kubernetes / Compute Resources / Node (Pods)可以看到每台机器,比如:
k8s-master
k8s-worker1
k8s-worker2如果图表里有数据,就说明 Prometheus 已经在正常采集指标了
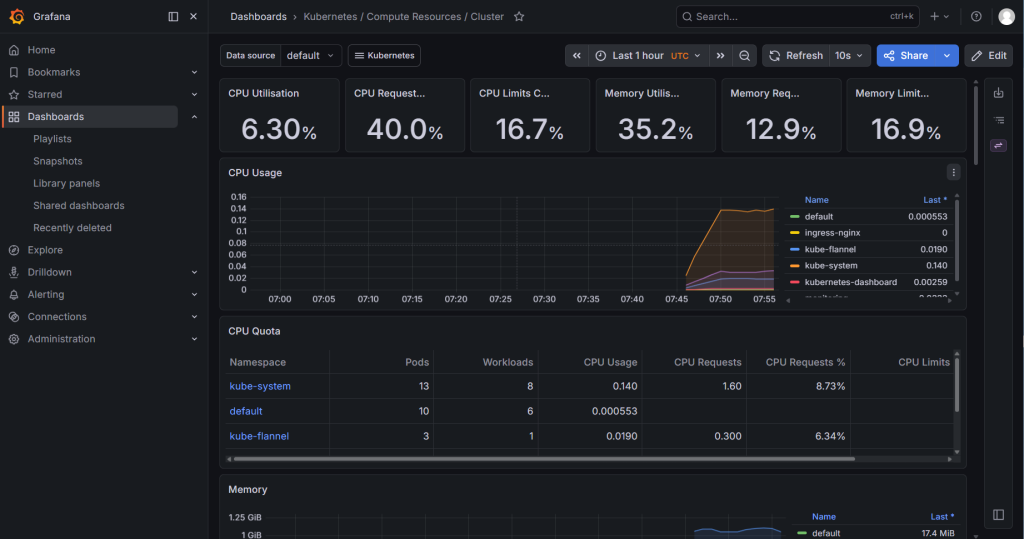
完美,Grafana 已经有数据了
这说明整条链路通了:
node-exporter / kube-state-metrics
↓
Prometheus 采集指标
↓
Grafana 展示图表我们去 Prometheus 页面验证一下采集目标。
打开:
http://172.16.11.142:30090然后点:
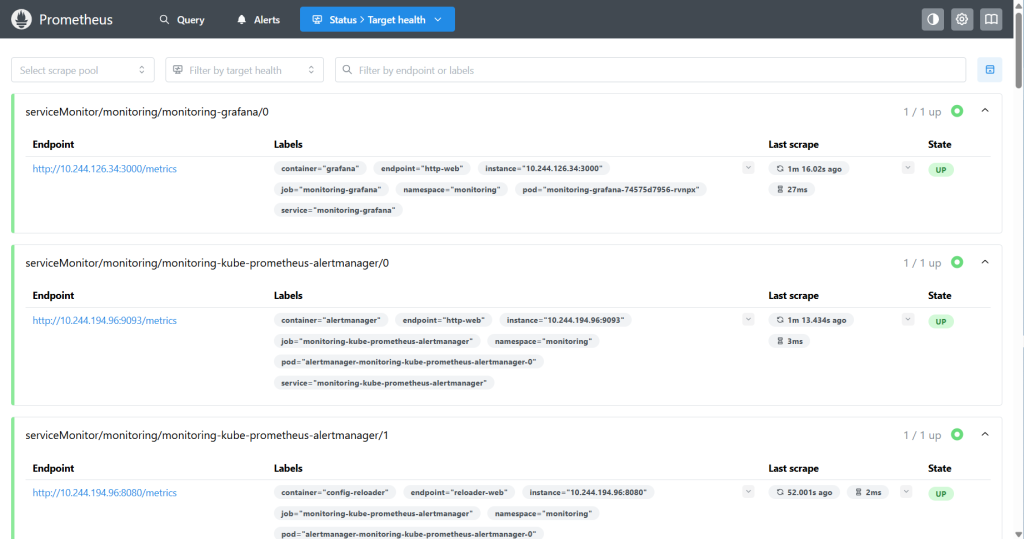
Status → Targets看看有没有大量 UP。
如果大部分是绿色 UP,说明监控采集目标正常。
先回到 Prometheus Query,查:
up
确认大部分是 1。
然后查节点指标:
node_cpu_seconds_total如果都有数据,第一阶段监控部署就算成功。
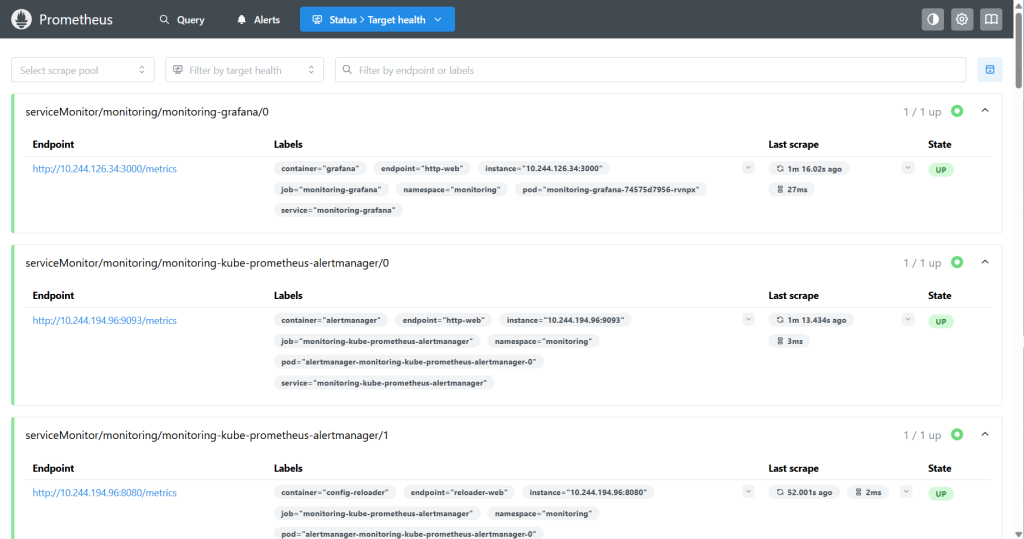
完美,Target 是绿色 UP
这说明:
Prometheus 已经能正常抓取监控目标
Grafana metrics 正常
Alertmanager metrics 正常
config-reloader metrics 正常你现在看到的:
1 / 1 up
State: UP意思是:
这个监控目标当前可达,并且 Prometheus 成功采集到了它的
/metrics数据。
下一步:查 PromQL 指标
点上方:
Query输入:
up点:
Execute如果出现很多条结果,并且 value 是 1,就说明采集整体正常。
然后我们再查一个节点指标:
node_cpu_seconds_total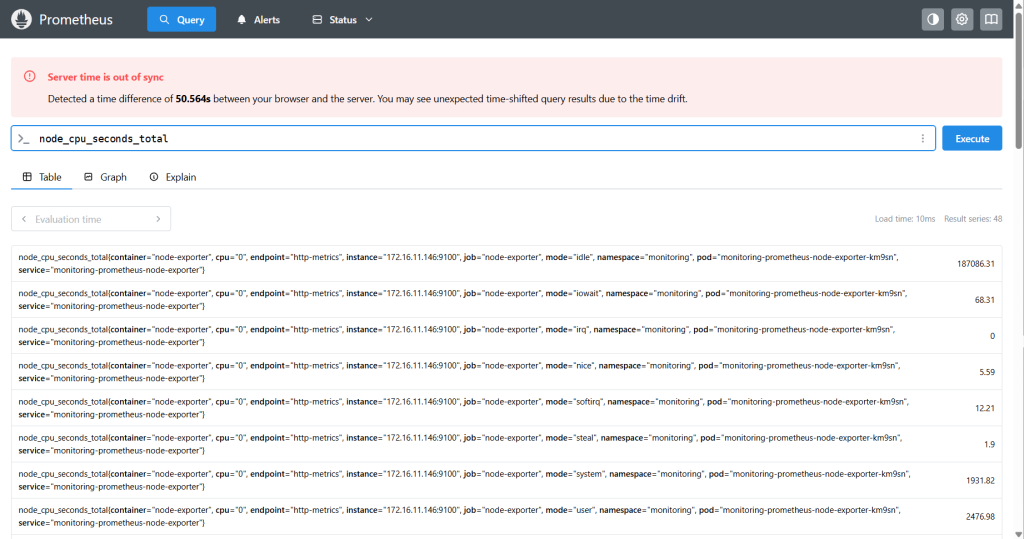
下一步我们处理这个红色提示:时间不同步
意思是:你的浏览器电脑时间和 K8S 节点时间差了大约 50 秒
第一步:在 master 查看时间
在 k8s-master 执行:
timedatectl再执行:
date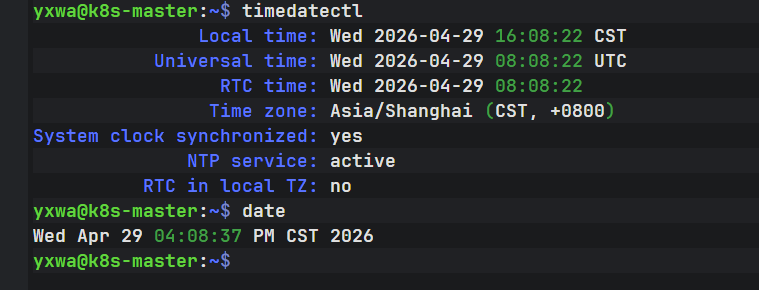
K8S master 这边其实是正常的:
System clock synchronized: yes
NTP service: active
Time zone: Asia/Shanghai原因大概率是:Windows 本机时间比 K8S 节点快了约 50 秒。
下一步:先同步 Windows 时间
在 Windows 上操作:
设置 → 时间和语言 → 日期和时间 → 立即同步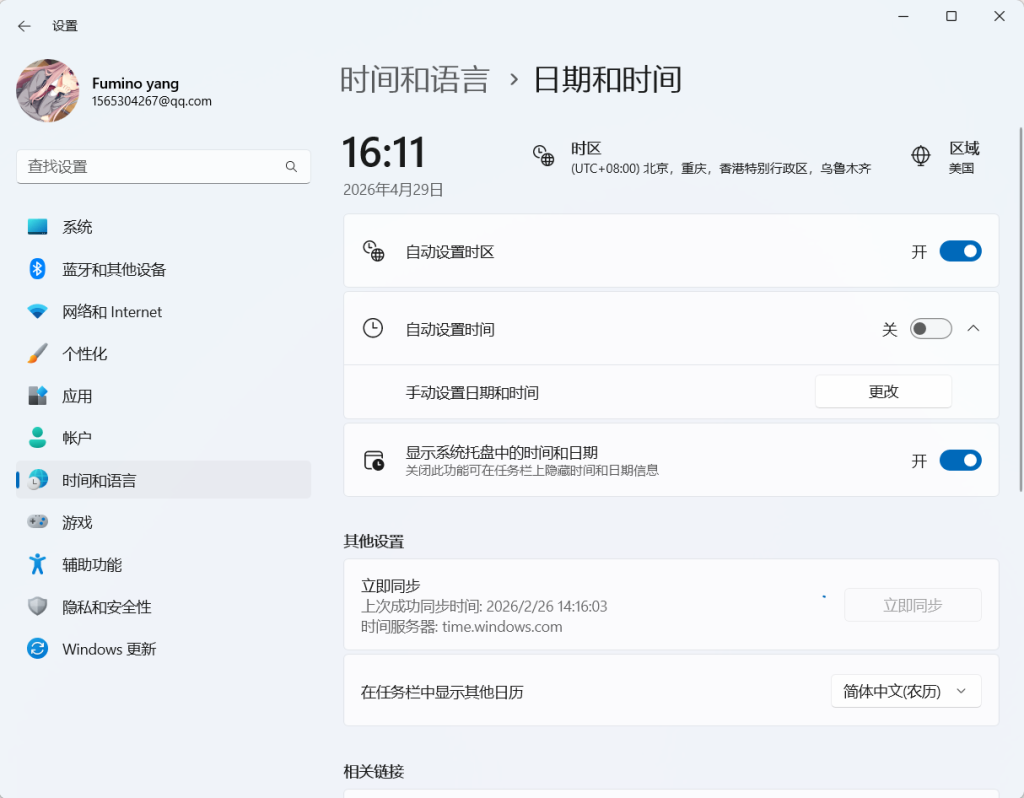
看来问题是
问题找到了:worker1 和 worker2 时间不一致
截图里:
worker1:16:13:27
worker2:16:14:01

这俩已经差了 34 秒,再加上 Windows 浏览器时间,所以 Prometheus 才一直提示差 50 秒左右
但是还是不行,,,,,,所以我不打算在这上面浪费太多的时间这个只是时间漂移提醒,不影响我们继续配置监控所以我最后一次尝试,奇迹般地成功了,原因在我的win11上面,请看步骤
先修 Windows 时间源
管理员 PowerShell 执行:
w32tm /config /manualpeerlist:"ntp.aliyun.com time.windows.com" /syncfromflags:manual /reliable:yes /update然后重启 Windows 时间服务:
net stop w32time
net start w32time再强制同步:
w32tm /resync /force查看状态:
w32tm /query /status重点看:
源:ntp.aliyun.com或者:
源:time.windows.com只要不再是 Local CMOS Clock,就对了
Alertmanager 告警规则和通知配置
这一阶段分两部分:
- 告警规则:Prometheus 什么时候判定出问题
- 通知配置:Alertmanager 把告警发到哪里
我们先做第 1 步:确认 Alertmanager 页面能打开
现在访问:
http://172.16.11.142:30093如果能打开 Alertmanager 页面,说明告警中心正常。
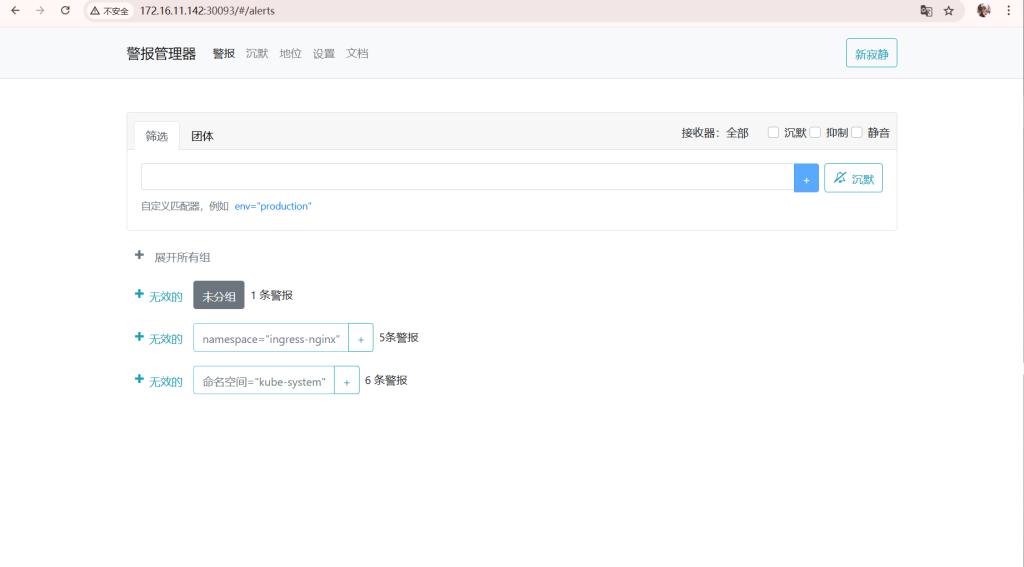
很好,Alertmanager 页面能打开
你现在已经有一些告警了:
ingress-nginx:5 条
kube-system:6 条
未分组:1 条页面里显示“无效的”不是说 Alertmanager 坏了,而是这些告警当前可能是:
pending / inactive / suppressed / resolved或者被 UI 翻译成了“无效的”。
下一步:先看 Prometheus 里的告警规则
打开 Prometheus:
http://172.16.11.142:30090点上面:
Alerts看里面有哪些告警是:
Firing
Pending
Inactive或者直接在 master 执行:
kubectl get prometheusrule -n monitoring再执行:
kubectl get prometheusrule -n monitoring | head
已经确认了:
PrometheusRule 规则存在
kube-prometheus-stack 默认告警规则已加载下一步我们看 Alertmanager 当前配置。
执行这一条:
kubectl get secret alertmanager-monitoring-kube-prometheus-alertmanager-generated \
-n monitoring \
-o jsonpath='{.data.alertmanager\.yaml\.gz}' | base64 -d | gunzip它会把 Alertmanager 当前配置解出来。
查看后发现,Alertmanager 当前默认配置如下:
global:
resolve_timeout: 5m
route:
receiver: “null”
group_by:
– namespace
routes:
– receiver: “null”
matchers:
– alertname = “Watchdog”
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receivers:
- name: “null”
可以看到,当前 receiver 是 null,也就是说 Alertmanager 虽然能接收到 Prometheus 发来的告警,但不会真正发送到邮箱、钉钉或企业微信等通知渠道
可以看到,当前 receiver 是 null,也就是说 Alertmanager 虽然能接收到 Prometheus 发来的告警,但不会真正发送到邮箱、钉钉或企业微信等通知渠道。
接下来我们配置邮箱告警
这里我选择使用 QQ 邮箱作为告警通知方式。收件邮箱:1565304267@qq.com
SMTP 服务器:smtp.qq.com
SMTP 端口:465注意:QQ 邮箱这里使用的是 SMTP/IMAP 授权码,不是 QQ 登录密码。修改 values-monitoring.yaml
nano values-monitoring.yaml找到原来的 alertmanager: 配置段,将其替换为:
# =========================
# Alertmanager 邮箱告警配置
# =========================
alertmanager:
enabled: true
service:
# 使用 NodePort 暴露 Alertmanager
type: NodePort
nodePort: 30093
config:
global:
# QQ 邮箱 SMTP 服务器
smtp_smarthost: 'smtp.qq.com:465'
# 发件邮箱
smtp_from: '你的QQ邮箱@qq.com'
# SMTP 用户名
smtp_auth_username: '你的QQ邮箱@qq.com'
# QQ 邮箱 SMTP 授权码,不是 QQ 密码
smtp_auth_password: '你的授权码'
# QQ 邮箱 465 SSL 端口,这里关闭 require_tls
smtp_require_tls: false
route:
# 默认告警接收器
receiver: 'email'
# 按告警名和命名空间分组
group_by: ['alertname', 'namespace']
# 首次告警等待 30 秒
group_wait: 30s
# 同组告警发送间隔
group_interval: 5m
# 重复告警间隔
repeat_interval: 1h
receivers:
- name: 'email'
email_configs:
- to: '你的QQ邮箱@qq.com'
send_resolved: true应用配置
helm upgrade monitoring prometheus-community/kube-prometheus-stack \
-n monitoring \
-f values-monitoring.yaml如果网络不稳定,可能会遇到:
unexpected EOF这是 Helm 下载 Chart 包时网络中断,不是 YAML 配置错误。
可以先手动下载 Chart 包:
helm pull prometheus-community/kube-prometheus-stack --version 84.3.0然后使用本地包更新:
helm upgrade monitoring ./kube-prometheus-stack-84.3.0.tgz \
-n monitoring \
-f values-monitoring.yaml
验证 Alertmanager 配置是否生效
kubectl get pods -n monitoring | grep alertmanager正常应该看到:
alertmanager-monitoring-kube-prometheus-alertmanager-0 2/2 Running再查看当前配置:
kubectl get secret alertmanager-monitoring-kube-prometheus-alertmanager-generated \
-n monitoring \
-o jsonpath='{.data.alertmanager\.yaml\.gz}' | base64 -d | gunzip如果看到:

就说明邮箱告警配置已经写入 Alertmanager。
7. 验证邮箱告警是否生效
升级完成后,先查看 Alertmanager 是否正常:
kubectl get alertmanager -n monitoring如果看到:
RECONCILED True
AVAILABLE True说明 Alertmanager 配置已经被 Prometheus Operator 正常同步。
示例:
NAME VERSION REPLICAS READY RECONCILED AVAILABLE
monitoring-kube-prometheus-alertmanager v0.32.0 1 1 True True然后查看 Alertmanager 当前实际配置:
kubectl get secret alertmanager-monitoring-kube-prometheus-alertmanager-generated \
-n monitoring \
-o jsonpath='{.data.alertmanager\.yaml\.gz}' | base64 -d | gunzip如果看到类似内容:
global:
resolve_timeout: 5m
smtp_from: 你的QQ邮箱@qq.com
smtp_smarthost: smtp.qq.com:465
smtp_auth_username: 你的QQ邮箱@qq.com
smtp_auth_password: 你的授权码
smtp_require_tls: false
route:
receiver: email
group_by:
- alertname
- namespace
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: "null"
- name: email
email_configs:
- send_resolved: true
to: 你的QQ邮箱@qq.com说明邮箱告警配置已经成功写入 Alertmanager。
这里需要注意一点:
receivers:
- name: "null"
- name: email为什么还要保留 null?
因为 kube-prometheus-stack 默认会把 Watchdog 这类测试告警发送到 null 接收器,避免它一直发送通知。如果删除 null,可能会出现:
undefined receiver "null" used in route所以最终配置里需要同时保留:
null:用于接收不需要真正通知的测试告警
email:用于发送真实告警邮件8. 邮箱收到告警
配置成功后,如果当前集群中已经存在告警,例如:
etcdMembersDown
TargetDown
KubePodNotReadyAlertmanager 会通过 QQ 邮箱发送告警邮件。
收到邮件后,说明完整链路已经打通:
PrometheusRule 触发告警
↓
Prometheus 进入 Firing 状态
↓
发送给 Alertmanager
↓
Alertmanager 根据 receiver=email 发送邮件
↓
QQ 邮箱收到告警9. 本阶段完成结果
到这里,Kubernetes 监控系统已经完成了:
Prometheus 指标采集
Grafana 图表展示
Alertmanager 告警管理
QQ 邮箱告警通知也就是说,我们已经实现了:
当 Kubernetes 集群中出现异常时,Prometheus 负责发现问题,Alertmanager 负责处理告警,并通过 QQ 邮箱通知管理员。
最终,QQ 邮箱成功收到了 Alertmanager 发送的告警邮件,说明 PrometheusRule、Prometheus、Alertmanager 和邮箱通知链路已经全部打通。
安全提醒
QQ 邮箱 SMTP 授权码不等于 QQ 密码,但它也属于敏感凭据。
生产环境中不建议直接把授权码明文写在 values-monitoring.yaml 里,更推荐使用 Kubernetes Secret 或外部密钥管理工具保存。
实验完成后,如果授权码曾经出现在截图、博客或终端记录中,建议到 QQ 邮箱后台删除该授权码,并重新生成新的授权码。